|
|
Математика ИИ
17 мая 2024 г. 17:00, г. Москва, Инновационный Центр «Сколково», Большой бульвар, 30, стр. 1, аудитория B4-3006.
|
 |
|
 |
|
|
|
Data dimensionality and Stochastic separation theorems
A. N. Gorban'
University of Leicester
|
| Количество просмотров: |
| Эта страница: | 97 |
|
Аннотация:
Artificial Intelligence (AI) systems sometimes make errors and will make errors in the future, from time to time. These errors are usually unexpected, and can lead to dramatic consequences. Intensive development of AI and its practical applications makes the problem of errors more important. Total re-engineering of the systems can create new errors and is not always possible due to the resources involved. The important challenge is to develop fast methods to correct errors without damaging existing skills.
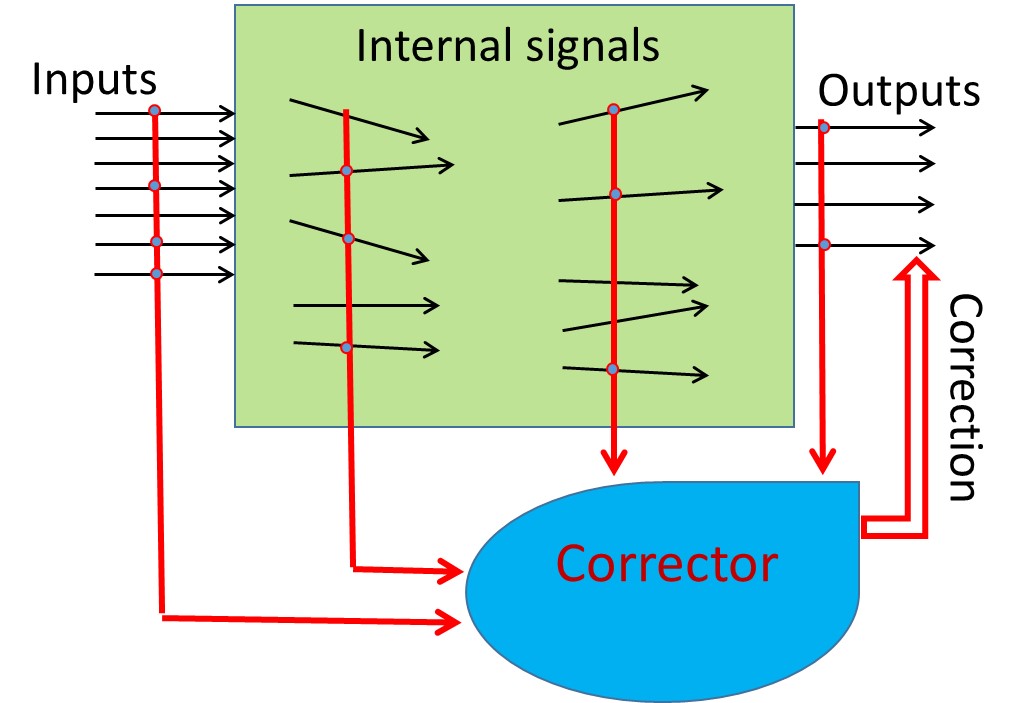
This work is driven by a practical question: corrections of Artificial Intelligence (AI) errors. These corrections should be quick and non-iterative. To solve this problem without modification of a legacy AI system, we propose special ‘external’ devices, correctors. Elementary correctors consist of two parts, a classifier that separates the situations with high risk of error from the situations in which the legacy AI system works well and a new decision for situations with potential errors. Input signals for the correctors can be the inputs of the legacy AI system, its internal signals, and outputs. If the intrinsic dimensionality of data is high enough then the classifiers for correction of small number of errors can be very simple. According to the blessing of dimensionality effects, even simple and robust Fisher's discriminants can be used for one-shot learning of AI correctors. Stochastic separation theorems provide the mathematical basis for this one-short learning.
In this lecture I plan to analyse the notion of data dimensionality and various methods of its evaluation. The software library for data dimensionality estimation is introduced.
Phenomenon of stochastic separability was revealed and used in machine learning to correct errors of Artificial Intelligence (AI) systems and analyze AI instabilities. In high-dimensional datasets under broad assumptions each point can be separated from the rest of the set by simple and robust Fisher's discriminant (is Fisher separable). Errors or clusters of errors can be separated from the rest of the data with high probability even for exponentially large data sets. Explicit and optimal estimates of separation probabilities are presented and examples of fast AI corrections are demonstrated.
Язык доклада: английский
|
|








 Обратная связь:
Обратная связь: